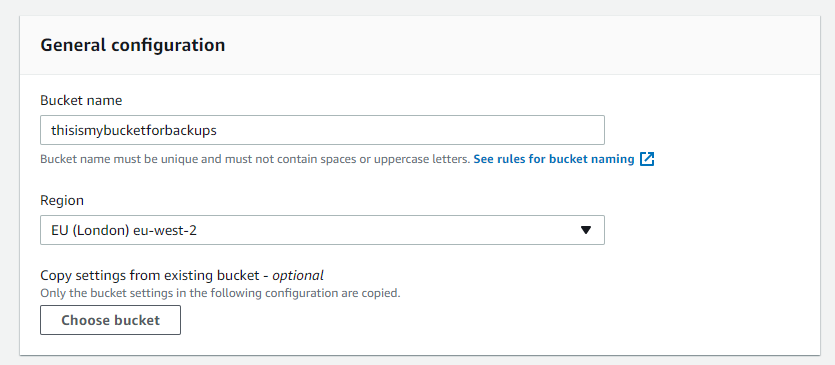
I have recently been experimenting and testing the Veeam API, however, I have noticed that there is a lack of information on how to work with it especially if you are new to the subject.
I love Python so it made sense to explorer the API using this, however, trying to communicate how to use it is a bit of a challenge. Enter Jupyter Notebooks.

If you are not already familiar with these, they essentially allow you to enter both markdown text and executeable python code into notebook ‘cells’.
The Markdown areas allow you to provide explaination of what you are doing in a logical fashion which makes it ideal for this type of use.
You can install Jupyter Labs which is the latest incarnation of Notebooks using:
pip install jupyterlabYou will need Python installed on your system (with it included in your PATH variables) for this to work. You then just need to run:
jupyter-labAlternativtley VS Code has direct support for Jupyter Notebooks so you can run them in there if you wish. Personally I find the Labs looks nicer but VS Code has intellisense which can be very useful.
I have uploaded a JP Notebook to my github which can be viewed here: